Можем ли мы обучить машинный алгоритм Google машинному обучению?
- Старые дни Google
- Google разъединяет обновления рейтинга
- Расщепление атомного алгоритма
- Прогнозирование и классификация алгоритмических сдвигов
- Резюме

Внедрение Google искусственного интеллекта заставило многих ошарашиться в поисковой оптимизации (SEO). Тактика оптимизации, которая работала годами, быстро устаревает или меняется.
Это почему? И можно ли найти предсказуемое уравнение оптимизации, как в старые времена? Вот внутренний совок.
Старые дни Google
Поисковая система Google с предварительным машинным обучением работала монолитно. То есть, когда произошли изменения, они пришли оптом. Большие и резкие движения, иногда тектонические, были обычным явлением в прошлом.
То, что относится к одному результату отрасли / поисковой системы, применяется ко всем результатам. Это не значит, что на каждую веб-страницу влияют все алгоритмические изменения. Каждый алгоритм влияет на определенный тип веб-страницы. Страница истории изменений алгоритма Моза подробно описывает долгую историю обновлений алгоритма Google и какие типы сайтов и страниц были затронуты.
Индустрия SEO началась с того, что люди расшифровывали эти обновления алгоритма и определяли, на какие веб-страницы они влияют (и как). Предприятия поднимались и опускались на фоне решений, принятых благодаря такому пониманию, и те, кто смог исправить курс достаточно быстро, стали победителями. Те, кто не мог выучить тяжелый урок.
Эти уроки превратились в «правила дорожного движения» для всех остальных, поскольку всегда была одна постоянная истина: алгоритмические штрафы были одинаковыми для каждой вертикали. Если ваш конкурент погибает, делая то, что Google не любит, вы будете уверены, что, если вы не совершите ту же ошибку, все будет в порядке. Но последние данные начинают показывать, что эта идиома SEO больше не работает. Машинное обучение сделало эти штрафы специфичными для каждой среды ключевых слов. У профессионалов SEO больше нет статического набора правил, по которым они могут играть.
Доктор Пит Мейерс, научный сотрудник Moz по маркетингу, недавно отметил: «Google прошел большой путь от эвристического подхода к подходу машинного обучения, но в 2016 году мы все еще далеки от понимания человеческого языка. , Чтобы действительно быть эффективными в качестве оптимизаторов, нам все еще нужно понимать, как мыслит этот механизм и где он не соответствует человеческому поведению. Если вы хотите по-настоящему исследовать ключевые слова следующего уровня, ваш подход может быть более человечным, но ваш процесс должен максимально полно отражать понимание машины ».
Moz собрал руководства и посты, связанные с пониманием новейшего искусственного интеллекта Google, в своей поисковой системе, а также выпустил новейший инструмент Keyword Explorer, который учитывает эти изменения.
Google разъединяет обновления рейтинга
Прежде чем приступить к объяснению того, как все пошло в гору для SEO, я сначала должен коснуться того, как технологии позволили поисковой системе Google перейти в ее текущее состояние.
Лишь недавно Google обладает вычислительной мощью, чтобы начать превращать обновления в режиме реального времени в реальность. 18 июня 2010 года Google обновил свою структуру индексации под названием « Кофеин », Что позволило Google быстрее обновлять свой поисковый индекс. Теперь веб-сайт может публиковать новый или обновленный контент и видеть обновления почти сразу в Google. Но как это работает?
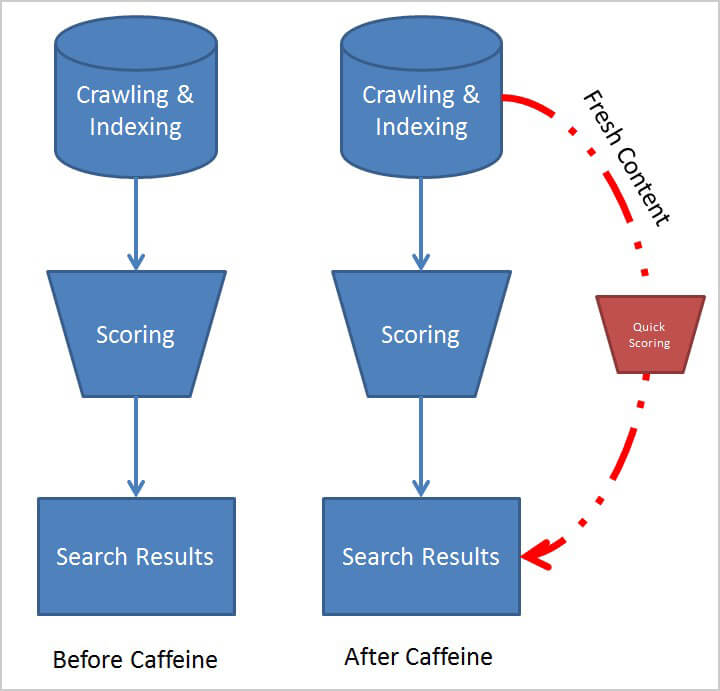
До обновления Caffeine Google работал как любая другая поисковая система. Он сканировал и индексировал свои данные, а затем отправлял эти индексированные данные через огромную сеть спам-фильтров и алгоритмов, которые определяли его возможный порядок на страницах результатов поисковой системы Google.
После обновления кофеина, однако, Выбор свежего контента может пройти сокращенный процесс оценки (временно) и сразу перейти к результатам поиска. , Незначительные вещи, такие как обновление тега заголовка страницы или мета-описания, или опубликованная статья для уже «проверенного» веб-сайта, будут кандидатами на этот новый процесс.
Звучит отлично, правда? Как оказалось, это создало огромный барьер для установления корреляции между тем, что вы изменили на своем сайте, и тем, как это изменение повлияло на ваш рейтинг. Отключение обновлений результатов поиска - и последующий возможный тщательный алгоритм алгоритмической оценки - по сути, заставили многих оптимизаторов поверить в то, что определенные оптимизации сработали, хотя на самом деле это не так.
Источник: официальный блог Google
Это было предвестником будущего Google, который больше не будет работать в серийном режиме. Блог Google эффективно прописал новая парадигма кофеина : «[E] самый второй кофеин обрабатывает сотни тысяч страниц параллельно».
С запутанной точки зрения, кофеин обеспечил широкое прикрытие основных сигналов рейтинга Google. Только дотошная команда SEO, которая тщательно изолировала каждое обновление, теперь могла расшифровать, какие оптимизации были ответственны за конкретные изменения ранжирования в этой новой среде параллельного алгоритма.
Когда я обратился к нему за комментариями, Маркус Тобер, основатель и технический директор Searchmetrics, сказал: «Сейчас Google рассматривает сотни факторов ранжирования. RankBrain использует машинное обучение для объединения многих факторов в один, что означает, что факторы взвешиваются по-разному для каждого запроса. Это означает, что очень вероятно, что даже инженеры Google не знают точного состава их очень сложного алгоритма ».
«С глубоким обучением оно развивается независимо от вмешательства человека. По мере развития поиска наш подход меняется с алгоритмическими изменениями Google. Мы анализируем темы, цели поиска и этапы продаж, потому что мы также используем методы глубокого обучения в нашей платформе. Мы подчеркиваем актуальность контента, потому что теперь Google отдает приоритет намерениям пользователей встречи ».
Эти изолированные циклы тестирования были теперь очень важны для определения корреляции, потому что ежедневные изменения в индексе Google не обязательно были связаны с изменениями рейтинга.
Расщепление атомного алгоритма
Как будто этого было недостаточно, в конце 2015 года, Google выпустил машинное обучение в своей поисковой системе , который продолжал отделять рейтинговые изменения от своих стандартных способов ведения дел в прошлом.
Как сообщил в TechCrunch ветеран индустрии Джон Рэмптон, основные алгоритмы в Google теперь работают независимо от того, что ищут. Это означает, что то, что работает для одного ключевого слова, может не работать для другого. Такое разделение поискового рейтинга Google с тех пор вызвало огромное горе в отрасли, так как традиционные инструменты, которые предписывают оптимизацию без разбора по миллионам ключевых слов, больше не могли работать на этом макроуровне. Теперь, искатель намерений буквально определяет, какие алгоритмы и факторы ранжирования более важны, чем другие в этой конкретной среде.
Это не следует путать с недавним объявлением о том, что будет отдельный индекс для мобильных и настольных компьютеров где четкое различие индексов будет присутствовать. Существуют различные инструменты, помогающие оптимизаторам понять свое место в отдельных индексах. Но как SEO работают с разными алгоритмами ранжирования в пределах одного индекса?
Задача состоит в том, чтобы классифицировать и анализировать эти алгоритмические сдвиги на основе ключевых слов. Одна из технологий, которая занимается этим и привлекает к себе большое внимание, была изобретена выпускником Карнеги-Меллона Скоттом Стоуффером. После того, как Google неоднократно пытался нанять его, Стоуффер решил вместо этого стать со-основателем корпоративной SEO-платформы под управлением AI под названием Market Brew, основанной на ряде патентов, выданных в последние годы.
Стоуффер объясняет: «Еще в 2006 году мы поняли, что в конечном итоге машинное обучение будет внедрено в процесс оценки Google. Как только это произошло, мы знали, что алгоритмические фильтры больше не будут статическим набором правил SEO. Поисковая система была бы достаточно умна, чтобы настраиваться на основе машинного обучения, что в прошлом работало лучше для пользователей. Таким образом, мы создали Market Brew, который, по сути, служит для «машинного обучения обучающегося».
«Наша общая модель поисковой системы может научиться выдавать результаты, очень похожие на реальные. Затем мы используем эти прогнозирующие модели как своего рода «песочницу Google», чтобы быстро A / B тестировать различные изменения на веб-сайте, мгновенно прогнозируя новые рейтинги для целевой поисковой системы бренда ».
Поскольку алгоритмы Google работают по-разному между ключевыми словами, Стуффер говорит, что больше нет четких границ. Комбинации ключевых слов и таких вещей, как намерение пользователя и предыдущие успехи и неудачи, определяют, как Google оценивает свои основные алгоритмы.
Прогнозирование и классификация алгоритмических сдвигов
Есть ли способ, как мы, как SEO, можем начать количественно понимать алгоритмические различия / веса между ключевыми словами? Как я упоминал ранее, существуют способы агрегирования этой информации с использованием существующих инструментов. На рынке также появилось несколько новых инструментов, которые позволяют командам SEO моделировать конкретные среды поисковых систем и прогнозировать, как эти среды изменяются алгоритмически.
Много ответов зависит от того, насколько конкурентоспособны и широки ваши ключевые слова. Например, бренд, который фокусируется только на одном первичном ключевом слове со многими вариантами последующих ключевых фраз длинного хвоста, скорее всего, не будет затронут этим новым способом обработки результатов поиска. Как только команда SEO выясняет ситуацию, они понимают это.
С другой стороны, если бренду приходится беспокоиться о множестве разных ключевых слов, которые охватывают разных конкурентов в каждой среде, тогда инвестиции в эти новые технологии могут быть оправданы. Командам SEO необходимо помнить, что они не могут просто применить то, что узнали в одной среде ключевых слов, к другой. Какой-то адаптивный анализ должен быть использован.
Резюме
Технология быстро приспосабливается к новой методологии поискового рейтинга Google. В настоящее время существуют инструменты, которые могут отслеживать каждое алгоритмическое обновление, определяя, какие отрасли и типы веб-сайтов подвержены наибольшему воздействию. Чтобы бороться с новым акцентом Google на искусственном интеллекте, мы теперь видим добавление новых инструментов моделирования поисковых систем, которые пытаются предсказать, какие именно алгоритмы меняются, чтобы оптимизаторы оптимизировали стратегии и тактику на лету.
Мы входим в золотой век SEO для инженеров и специалистов по данным. По мере того как алгоритмы Google продолжают усложняться и переплетаться, индустрия SEO ответила новыми мощными инструментами, помогающими понять этот новый мир SEO, в котором мы живем.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Это почему?И можно ли найти предсказуемое уравнение оптимизации, как в старые времена?
Но как это работает?
Звучит отлично, правда?