Screaming Frog SEO Spider Обновление - Версия 6.0
- 1) Рендеринг сканирования (JavaScript)
- 2) Настраиваемые столбцы и порядок
- 3) XML Sitemap & Sitemap Сканирование индекса
- 4) Улучшенное пользовательское извлечение - несколько значений и функций
- 5) rel = «next» и rel = «prev» Элементы теперь просканированы
- 6) Обновлен эмулятор сниппета SERP
- Другие обновления
- Небольшое обновление - версия 6.1 выпущена 3 августа 2016 г.
- Обновление - версия 6.2 выпущена 16 августа 2016
Я рад объявить о версии 6.0 Screaming Frog SEO Spider, внутренне закодированном как «render-Rooney».
Наша команда была занята в разработке и имеет несколько очень интересных новых функций, готовых к выпуску в последнем обновлении. Это включает в себя следующее -
1) Рендеринг сканирования (JavaScript)
В начале года мы намеревались сделать две вещи. Во-первых, точно понять, что поисковые системы могут сканировать и индексировать. Вот почему мы создали Screaming Frog Анализатор лог-файлов , поскольку сканер будет только симуляцией поведения поискового бота.
Во-вторых, мы хотели сканировать визуализированные страницы и читать DOM. Давно известно, что робот Googlebot действует больше как современный браузер, довольно хорошо отображающий контент, сканирующий и индексирующий JavaScript и динамически генерируемый контент. SEO Spider теперь может отображать и сканировать веб-страницы аналогичным образом.
Вы можете выбрать, следует ли сканировать статический HTML, подчиняться старой схеме сканирования AJAX или полностью отображать веб-страницы, что означает выполнение и сканирование JavaScript и динамического содержимого.

Google не одобрил их старую схему сканирования AJAX, и мы видели, как JavaScript-фреймворки, такие как AngularJS (со ссылками или с использованием HTML5 History API), сканируются, индексируются и ранжируются как типичный статический HTML-сайт. Я настоятельно рекомендую прочитать Тестирование Адамом Одеттом в Googlebot JavaScript с прошлого года, если вы еще не знакомы.
После долгих исследований и испытаний мы интегрировали библиотеку проектов Chromium для нашего движка рендеринга, чтобы максимально эмулировать Google. Некоторые из вас могут вспомнить отличное Googlebot - это Chrome 'сообщение от Джошуа Джи в блоге Майка Кинга в 2011 году, в котором говорится, что робот Google по сути является браузером без головы.
Новый режим рендеринга действительно мощный, но есть несколько вещей, которые нужно помнить -
- Обычно сканирование медленнее, даже если оно все еще многопоточное, так как SEO Spider должен дольше ждать загрузки контента и собирать все ресурсы для отображения страницы. Наше внутреннее тестирование предлагает Google подождать примерно 5 секунд для отображения страницы, поэтому это время ожидания AJAX по умолчанию в SEO Spider. Google может настроить это в зависимости от ответа сервера и других сигналов, поэтому вы можете настроить его в соответствии со своими требованиями, если сайт загружает страницу медленнее.
- Сканирование совершенно иное, так как может потребоваться время для появления чего-либо в пользовательском интерфейсе, а затем внезапно появляется множество URL-адресов одновременно. Это связано с тем, что SEO Spider ожидает загрузки всех ресурсов для отображения страницы перед отображением данных.
- Чтобы правильно отображать контент, такие ресурсы, как JavaScript и CSS, не должны быть заблокированы от SEO Spider. Вы можете увидеть URL-адреса, заблокированные robots.txt (и соответствующей запрещающей строкой robots.txt) в разделе «Коды ответов> Заблокировано Robots.txt». Вы также должны убедиться, что вы сканируете JS, CSS и внешние ресурсы в конфигурации SEO Spider.
Также важно отметить, что, поскольку SEO Spider отображает контент, как браузер, с вашего компьютера, это может повлиять на аналитику и все остальное, что зависит от JavaScript.
По умолчанию SEO Spider исключает выполнение тегов JavaScript Google Analytics в своем движке, однако, если сайт использует другие аналитические решения или JavaScript, которые не должны выполняться, не забудьте использовать исключить особенность ,
2) Настраиваемые столбцы и порядок
Теперь вы можете настроить, какие столбцы будут отображаться на каждой вкладке SEO Spider (нажав «+» в верхней части окна).

Вы также можете перетаскивать столбцы в любом порядке, и это запомнится (даже после перезапуска).
Чтобы вернуться к столбцам и порядку по умолчанию, просто щелкните правой кнопкой мыши символ «+» и нажмите «Сбросить столбцы» или выберите «Конфигурация> Интерфейс пользователя> Сбросить столбцы для всех таблиц».
3) XML Sitemap & Sitemap Сканирование индекса
SEO Spider уже позволяет сканировать карты сайта XML в режиме списка, загружая файл .xml (номер 8 в 10 функций в SEO Spider, которые вы должны знать 'post), который всегда был немного неуклюжим, чтобы сохранить его, если он был уже живым (но удобным, когда он не был загружен!).
Итак, теперь мы ввели возможность ввести URL-адрес карты сайта для ее сканирования («Режим списка> Загрузить файл Sitemap»).
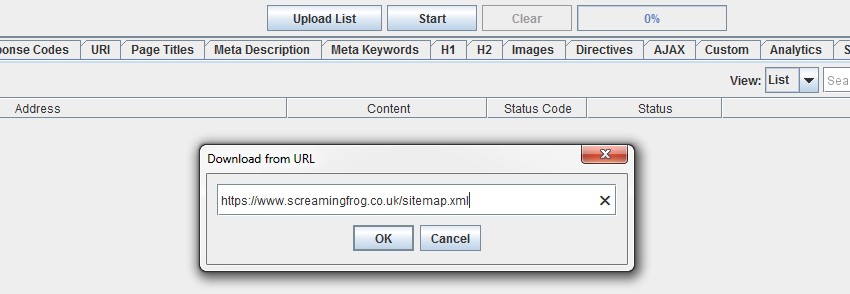
Раньше, если на сайте было несколько файлов Sitemap, вам также приходилось загружать и сканировать их отдельно.
Теперь, если у вас есть индексный файл карты сайта для управления несколькими картами сайта, вы можете ввести URL-адрес индексного файла карты сайта, и SEO Spider загрузит все карты сайта и последующие URL-адреса в них!
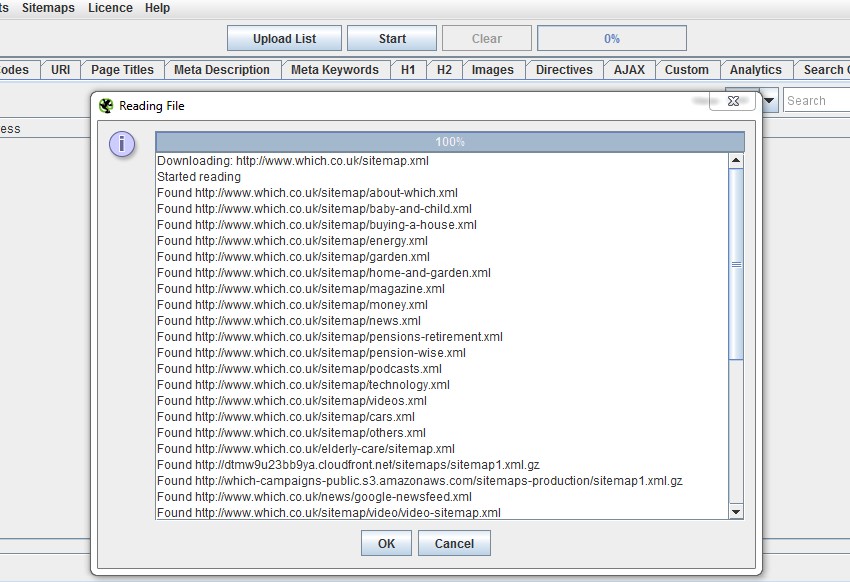
Это должно помочь сэкономить много времени!
4) Улучшенное пользовательское извлечение - несколько значений и функций
Мы выслушали отзывы о том, что пользователи часто хотят извлечь несколько значений, не используя несколько экстракторов. Например, ранее для сбора 10 значений вам нужно было использовать 10 экстракторов и селекторов индексов ([1], [2] и т. Д.) С XPath.
Мы изменили это поведение, поэтому по умолчанию один экстрактор будет собирать все найденные значения и сообщать о них через один экстрактор для XPath, CSS Path и Regex. Если у вас есть 20 значений hreflang, вы можете использовать один экстрактор, чтобы собрать их все, и SEO Spider динамически добавит дополнительные столбцы, сколько потребуется. У вас останется еще 9 экстракторов для игры. Таким образом, один XPath, такой как -

Теперь соберу все обнаруженные значения.

Вы все еще можете выбрать извлечение только первого экземпляра, используя также селектор индекса. Например, если вы просто хотите собрать первый h3 на странице, вы можете использовать следующий XPath:

Функции также можно использовать в любом месте XPath, но теперь вы можете использовать их и в раскрывающемся меню «значение функции». Поэтому, если вы хотите подсчитать количество ссылок на странице, вы можете использовать следующий XPath:

Я бы рекомендовал прочитать наше обновленное руководство по соскоб для дополнительной информации.
5) rel = «next» и rel = «prev» Элементы теперь просканированы
Теперь SEO Spider может сканировать элементы rel = «next» и rel = «prev», тогда как ранее инструмент просто сообщал о них. Теперь, если URL-адрес еще не был обнаружен, он будет добавлен в очередь, и URL-адреса будут сканироваться, если включена конфигурация («Конфигурация> Паук> Вкладка« Основные »> Сканирование далее / Предыдущая»).
Элементы rel = «next» и rel = «prev» не считаются «Inlinks» (в нижней вкладке окна), поскольку они не являются ссылками в традиционном смысле. Следовательно, если URL не имеет никаких «Inlinks» в сканировании, это может быть связано с обнаружением по rel = «next» и rel = «prev» или каноническому. Мы рекомендуем использовать «Отчет о пути сканирования», чтобы показать, как была обнаружена страница, где будет показан полный путь.
Также имеется новый параметр конфигурации «соблюдать следующий / предыдущий» (в разделе «Конфигурация> Паук> вкладка« Дополнительно »»), который будет скрывать любые URL-адреса с элементом «предыдущий», поэтому они не считаются дубликатами первой страницы серии.
6) Обновлен эмулятор сниппета SERP
В начале мая этого года Google увеличил ширину столбца органических SERP с 512 пикселей до 600 пикселей на рабочем столе, что означает, что фрагменты заголовков и описаний длиннее. Google отображает и усекает фрагменты SERP на основе ширины пикселя символов, а не количества символов, что может затруднить оптимизацию.
Наше предыдущее исследование показало, что Google использовал для усечения заголовков страниц около 482 пикселей на рабочем столе. После внесения изменений мы обновили наши исследования и логику в эмуляторе фрагментов SERP, чтобы они соответствовали новой точке усечения Google до эллипса (…), который для заголовков страниц на рабочем столе составляет около 570 пикселей.
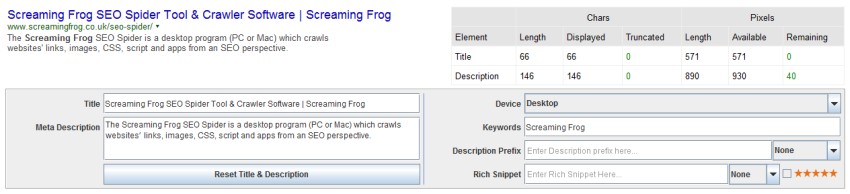
Наши исследования показывают, что, хотя пространство для описаний также увеличилось, они все еще усекаются намного раньше, в аналогичном месте с более ранней SERP шириной 512 пикселей. Эмулятор фрагмента SERP будет выделять только ключевые слова в описании фрагмента, а не в заголовке, так же, как в поисковой выдаче Google.
Обратите внимание: вы можете время от времени видеть наш эмулятор фрагмента SERP как слово в любом направлении по сравнению с тем, что вы видите в Google SERP. Всегда будут некоторые различия в пикселях, что означает, что граница пикселей может не совпадать с той же точкой, которую Google рассчитывает в 100% случаев.
Время от времени мы все еще видим, что Google play использует другие правила, где некоторые фрагменты имеют более длинную точку отсечения пикселей, особенно для описаний! Следовательно, эмулятор фрагмента SERP не всегда точен, но имеет хорошее практическое правило.
Другие обновления
Мы также включили некоторые другие небольшие обновления и исправления ошибок в версии 6.0 Screaming Frog SEO Spider, которые включают следующее:
- На внутренней вкладке введен новый столбец «Соотношение текста», в котором рассчитывается соотношение текста к HTML.
- Google обновил свой API Search Analytics, поэтому теперь SEO Spider может получать более 5 тыс. Строк данных из консоли поиска.
- Для консоли поиска появился новый «фильтр поисковых запросов», который позволяет пользователям включать или исключать ключевые слова (в разделе «Конфигурация> Доступ к API> Консоль поиска Google> вкладка Измерения»). Это должно быть полезно для исключения запросов бренда, например.
- Существует новая конфигурация для извлечения изображений из атрибута IMG srcset в «Конфигурация> Дополнительно».
- Новый Googlebot смартфон пользовательский агент был включен.
- Обновлена наша поддержка относительных базовых тегов.
- Убрана пустая строка в начале экспорта в Excel.
- Исправлена ошибка с количеством слов, которая могла сделать его менее точным.
- Исправлена ошибка с номерами GTR CTR.
Я думаю, что это почти все! Как всегда, пожалуйста, сообщите нам, если у вас есть какие-либо проблемы или обнаружите какие-либо ошибки.
Спасибо всем за поддержку и постоянную обратную связь. Приносим извинения за любые функции, которые мы не смогли включить в это обновление, мы уже работаем над следующим набором обновлений, и это еще не все!
Теперь иди и скачать версия 6.0 SEO Spider !
Небольшое обновление - версия 6.1 выпущена 3 августа 2016 г.
Мы только что выпустили небольшое обновление до версии 6.1 SEO Spider. Этот выпуск включает в себя -
- Обновление 66 для Java 8 теперь требуется на всех платформах, так как это обновление исправляет несколько ошибок в Java.
- Уменьшена проверка сертификата, чтобы быть более терпимым при сканировании сайтов HTTPS.
- Исправлен сбой при использовании конфигурации диапазона дат для интеграции с Google Analytics.
- Исправлена проблема с нижней панелью окна, скрывающая главное окно данных для некоторых пользователей.
- Исправлен сбой в пользовательском извлечении.
- Исправлена ошибка в режиме рендеринга JavaScript, когда агент JS navigator.userAgent не был правильно настроен, из-за чего сайты, выполняющие профилирование UA в JavaScript, не работали.
- Исправлен сбой при запуске сканирования без выбора в окне обзора.
- Исправлена проблема со слишком строгим разбором тегов заголовков. Google, кажется, использует их независимо от допустимых элементов заголовка HTML.
- Исправлен сбой для 32-битных пользователей Windows XP / Vista / Server 2003 / Linux, которые не поддерживается для режима рендеринга ,
Обновление - версия 6.2 выпущена 16 августа 2016
Мы только что выпустили небольшое обновление до версии 6.2 SEO Spider. Этот выпуск включает в себя -
- Исправлено несколько сбоев.
- Исправлена ошибка для unavailable_after в фильтре директив.
- Исправьте двойной щелчок по файлам .seospider в OS X, который не загружал файл сканирования.
- Несколько экземпляров извлечения теперь сгруппированы вместе.
- Экспорт теперь учитывает порядок столбцов и предпочтения видимости.